Plauti Deduplicate uses scenarios to identify duplicate records in Salesforce. In a scenario you decide which fields and which logic Plauti Deduplicate should use when comparing records to see if they are duplicates. Furthermore, you can define from which level of similarity two records should be considered duplicate. 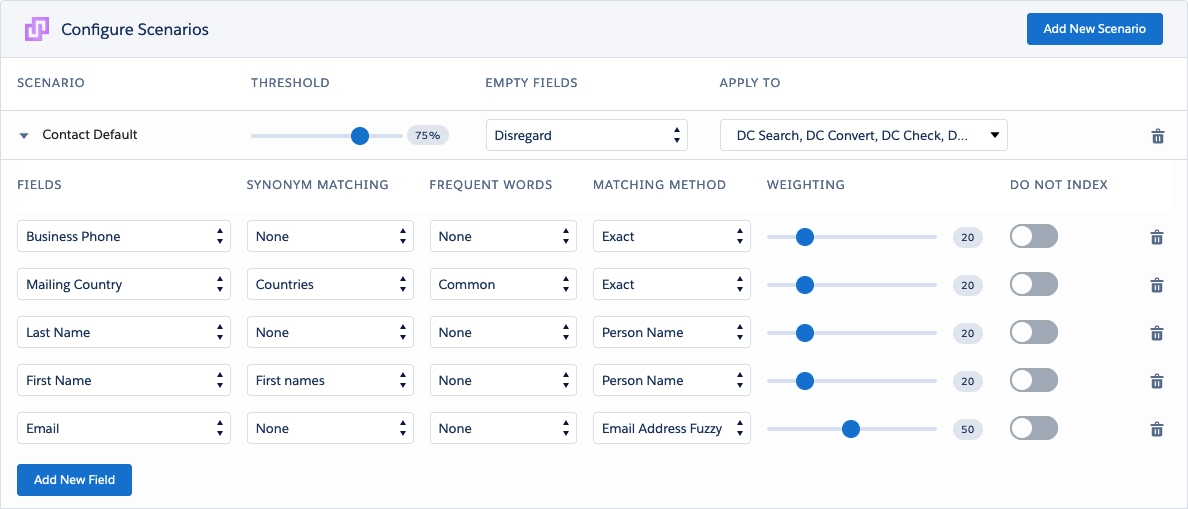
Edit name
Edit a scenario name by clicking the pencil icon next to the name. The icon will become visible when you move your mouse over the scenario name.

Threshold
In the process of comparing records, Duplicate Check calculates a matching percentage: the matching score. That percentage is calculated by comparing the values of the fields that are defined in your scenario. The Threshold level decides from what percentage a match is defined as a potential duplicate record. The default setting is 75%: every score equal to or higher than 75% will be defined as a potential duplicate record. This means that a match between two (or more) records can deviate with a maximum of 25% in its values.

If you set the Threshold level at 100%, the scenario will only return results that have an exact match on all of the fields defined in it.
Fields
Your scenario is a strategy on how to compare records and find duplicates. The fields defined in the scenario are the fields used to compare records. The Lead Default scenario (standard configuration) uses the First Name, Last Name, Company Name, and Phone field. You can remove fields from your scenario by clicking the 'Delete' icon at the end of the table. Adding a new field is easy. Just click the 'Add new field' button.
Synonym Matching
At Synonym Matching, select a list of synonyms for the possible values of this field. Synonyms in this context are words that are different from each other, but that should be considered duplicates of each other. Applying a synonyms list will improve the accuracy of a duplicate score. Find out more about synonym matching in this article.
Frequent Words
At Frequent Words, select a list of frequent words for the possible values of this field. Frequent Words are common words that will not be taken into account when checking for duplicate values for this field. Applying a frequent words list will improve the accuracy of a duplicate score. Find out more about frequent words in this article.
Matching method
Matching Methods are algorithms used by Plauti Deduplicate to analyze field values of standard and custom fields. Based on this analysis it decides to what extent two records match: the matching score.
Fields can have different value types (e.g. numeric or text, but also plain text or email addresses, etc.) In order to catch duplicate records it is important to apply a matching method that can properly analyze each value type.
With a matching method you also decide to apply an exact or fuzzy logic to evaluate field values.
Select a matching method for each scenario field, based on the field type.
Find out more about matching methods in this article.
Empty fields
In most databases, not all fields of every record are populated. The 'Empty Fields' setting lets you configure how to handle empty fields in the comparison process. You can choose between three options.
1. Disregard
"Disregard" will not take empty fields into account when calculating a matching percentage. It can still trigger a 100% score if there are one or more fields without value. Using this setting, we allow you to find duplicate records that are not filled out entirely. "Disregard" can, however, also trigger false positives. If so, please check out the other setting options. These example scores are calculated with an equal weighting for all fields.
| First Name | Last Name | Company name | Email Address | Phone number | Score |
| Jennifer | Blake | Laoreet Corporation | j.blake@loareet.com | 1-817-297-7931 | 100% |
| Jennifer | Blake | Laoreet Corporation | Empty | 1-817-297-7931 |
Or
| First Name | Last Name | Company Name | Email Address | Phone Number | Score |
| Jennifer | Blake | Laoreet Corporation | j.blake@laoreet.com | 1-817-297-7931 | 100% |
| Jennifer | Empty | Empty | Empty | Empty |
2. Score 50%
Instead of disregarding empty values, "Score 50%" will take empty fields into account for 50% in the calculation process. As a result, the matching percentage is lower.
| First Name | Last Name | Company name | Email Address | Phone number | Score |
| Jennifer | Blake | Laoreet Corporation | j.blake@laoreet.com | 1-817-297-7931 | 90% |
| Jennifer | Blake | Laoreet Corporation | Empty | 1-817-297-7931 |
3. Score 0%
"Score 0%" will assign empty fields a matching score of 0%. As a result, the difference between the two field values is considered a non-match. The matching percentage will be lower.
| First Name | Last Name | Company Name | Email Address | Phone number | Score |
| Jennifer | Blake | Laoreet Corporation | j.blake@laoreet.com | 1-817-297-7931 | 80% |
| Jennifer | Blake | Laoreet Corporation | Empty | 1-817-297-7931 |
Depending on your 'Empty Fields' setting, your scenario could calculate a 100% score based on one field, even if there are more fields defined in your scenario.
Apply to
Decide to which feature of Duplicate Check for Salesforce you want to apply this search scenario. You can choose any number of features.
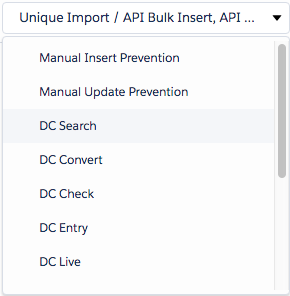
Manual Insert Prevention
Manual Update Prevention
DC Search
DC Convert
DC Check
DC Entry
DC Live
DC Job
Unique Import / API Bulk Insert
API Single Insert / Update
DC Apex API
Web to Lead
Data API
Weighting
Use the weighting setting to decide which fields matter the most when comparing records. A field with a higher weight impacts the matching percentage more than a field with a lower weight.
Example 1: Weighting equal to all fields
| Field | Matching Method | Weighting |
| First Name | Exact | 10 (10/50 = 20%) |
| Last Name | Exact | 10 (10/50 = 20%) |
| Company | Exact | 10 (10/50 = 20%) |
| Exact | 10 (10/50 = 20%) | |
| Phone | Exact | 10 (10/50 = 20%) |
| First Name | Last Name | Company Name | Email Address | Phone Number | Score |
| Jennifer | Blake | Loareet Corporation | j.blake@loareet.com | 1-817-297-7931 | 80% |
| Jennifer | Blake | Loareet Corporation | different@mail.com | 1-817-297-7931 |
Example 2: More weight on Email Address
Field |
Matching Method | Weighting |
| First Name | Exact | 10 (10/60 = 16.6%) |
| Last Name | Exact | 10 (10/60 = 16.6%) |
| Company | Exact | 10 (10/60 = 16.6%) |
| Exact | 20 (20/60 = 33.3%) | |
| Phone | Exact | 10 (10/60 = 16.6%) |
| First Name | Last Name | Company Name | Email Address | Phone Number | Score |
| Jennifer | Blake | Laoreet Corporation | j.blake@laoreet.com | 1-817-297-7931 | 67% |
| Jennifer | Blake | Laoreet Corporation | different@email.com | 1-817-297-7931 |
